
[CS231] Lec6. CNN Architectures
📢Key Words: Batch Normalization, AlexNet, GoogleNet, ResNet, Transfer Learning
각종 CNN 아키텍처들을 알아본다.
1. Batch Normalization
- https://www.youtube.com/watch?v=m61OSJfxL0U
- 위의 강의를 통해 보다 수월하게 이해할 수 있었다.
01. Batch Normalization
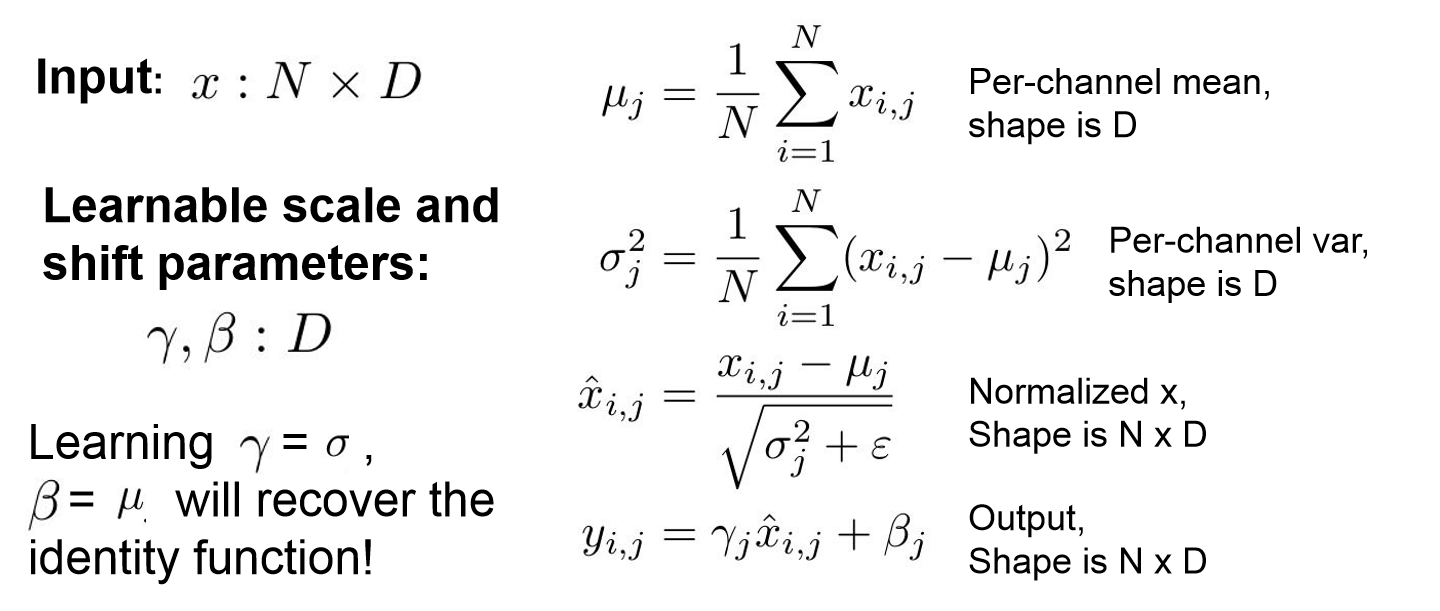 Batch Normalization
Batch Normalization
- Mini-batch를 통한 데이터가 zero-centered하지 않을 수 있기에 이를 mini-batch의 평균과 분산으로 정규화시켜 보다 원할한 학습이 가능하도록 해주는 것이다.
- 보통 FC layer or Conv layer 뒤나 activation function 전에 적용한다.
- 적절한 평균과 분산으로 데이터를 모아주기에 gradient vanishing 문제를 방지할 수 있고, 초기에 데이터를 정규화 시켜주기에 learning rate를 보다 크게 가져갈 수 있어 빠르게 학습을 진행할 수 있다.
02. Group Normalization
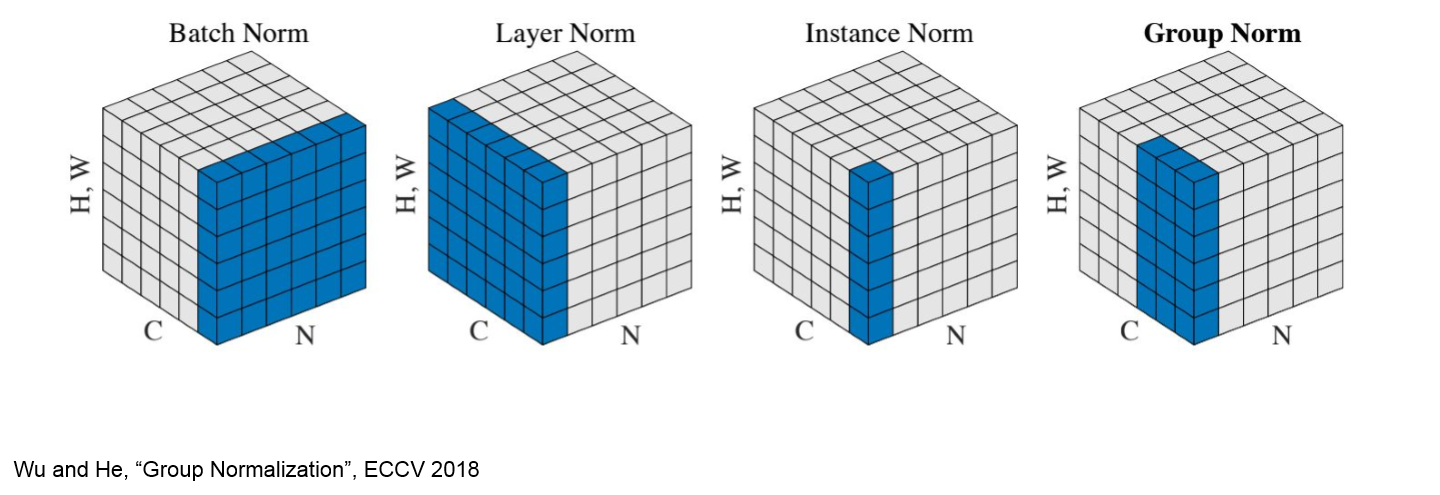 Normalization 종류
Normalization 종류
- Batch의 크기가 작을 때 유용한 다른 normalization 기법들이 있다.
- Layer Normalization은 channel과 이미지를 모두 normlaize 해주는 것이고, Instance Normalization은 각 channel 단위로 독립적으로 normalize 해준다.
- Gropu Normalization은 각 채널을 N개의 grop으로 나눠 normalize해주는 기술이다.
- Grop Norm의 G 값이 1이면 Layer Norm과 동일하게 되고 G=C이면 Insatnace Norm과 동일해 지는 것을 확인할 수 있다.
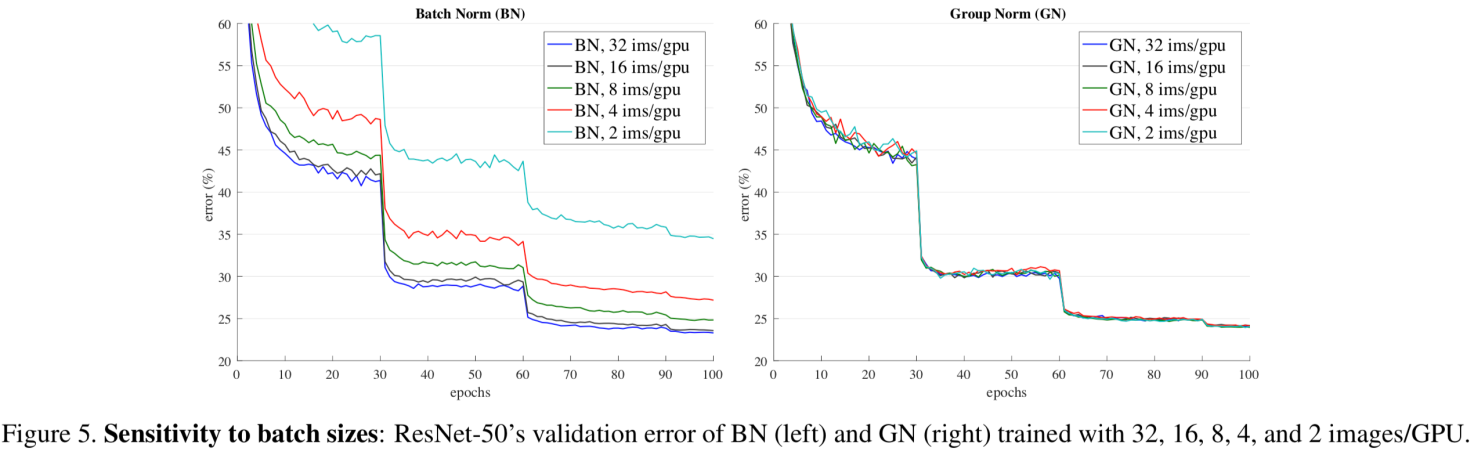 Normalization에 따른 성능 차이
Normalization에 따른 성능 차이
- 위의 ResNet-50을 이용해 실험한 결과를 보면 Group Normalization이 Layer Normalization이나 Instance normalization보다 좋은 성능을 내는 것을 확인할 수 있다.
Group Normalization
- 위의 이미지를 보면 group normalization은 batch 수와 상관없이 비슷한 성능을 내는 것을 확인할 수 있다.
2. CNN Architectures
01.AlexNet
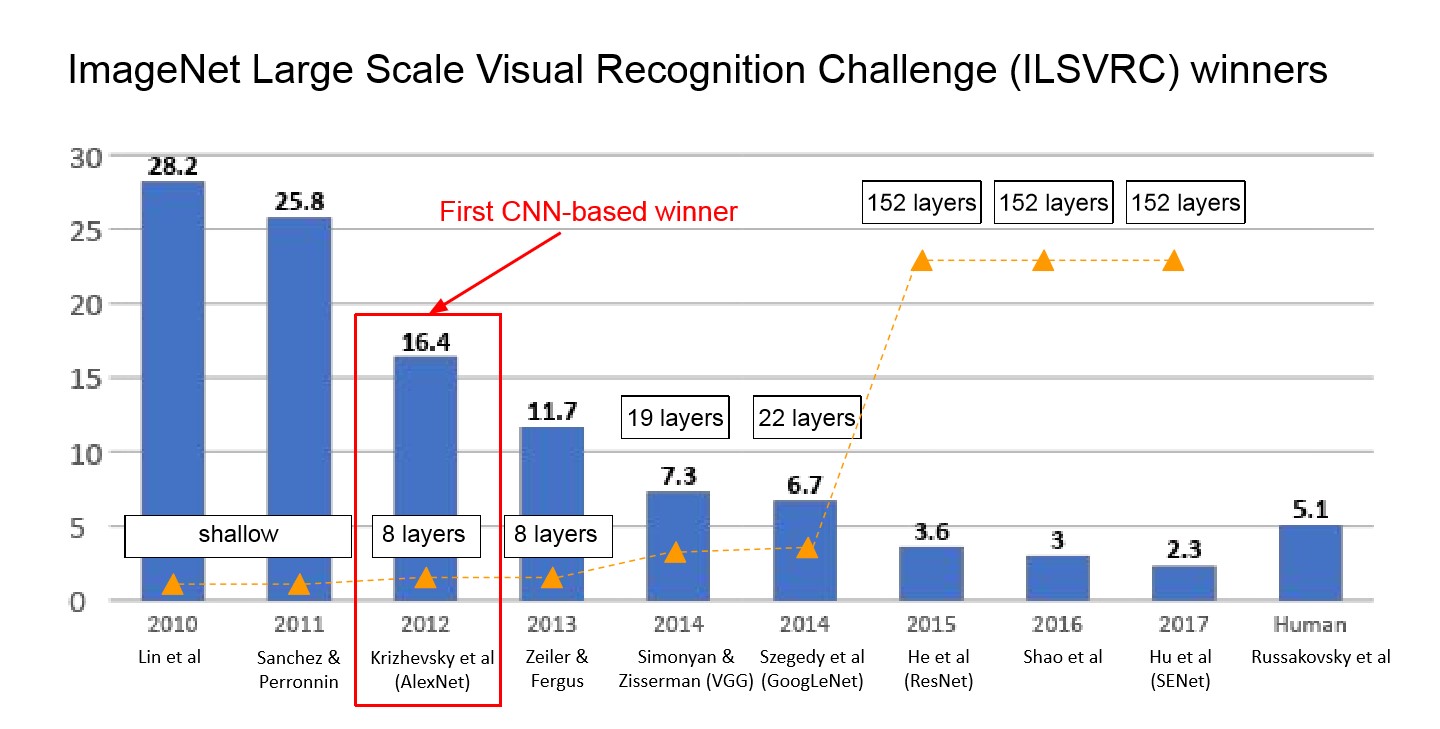 연도별 ImageNet 대회 우승팀
연도별 ImageNet 대회 우승팀
- ImageNet 대회에서 Convolution layer를 도입하여 우승한 첫 신경망이 AlexNet이다.
 AlexNet 구조
AlexNet 구조
- Convolution layer를 처음 도입한 LeNet과 다른점은, 2개의 GPU로 병렬연산을 수행하기 위해서 병렬적인 구조로 설계되었다는 점이라고 한다.
- 5개의 컨볼루션 레이어와 3개의 fully connected 레이어로 구성되어 있다.
- AlexNet의 몇가지 특징은 아래와 같다.
- ReLU를 처음 도입
- Data augmentation을 많이 사용
- Dropout: 0.5
- Batch size: 128
- SGD Momentum: 0.9
- Learning rate: 1e-2, 정체마다 수동 감소
- L2 weight decay 5e-4
- 7 CNN ensemble: 18,2% -> 15.4%
02.ZFNet
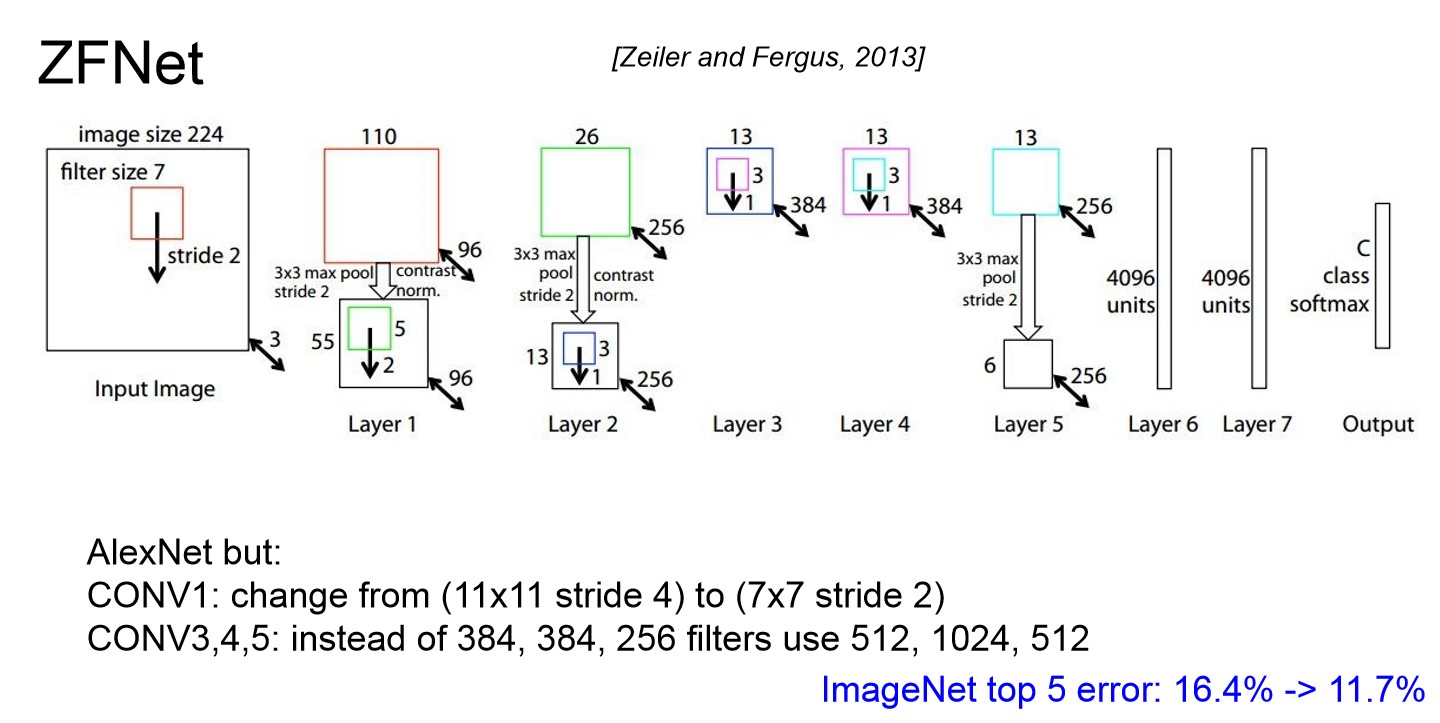 ZFNet
ZFNet
- AlexNet에서 Convolution layer의 구성을 바꿔 성능을 높였다.
03.VGGNet
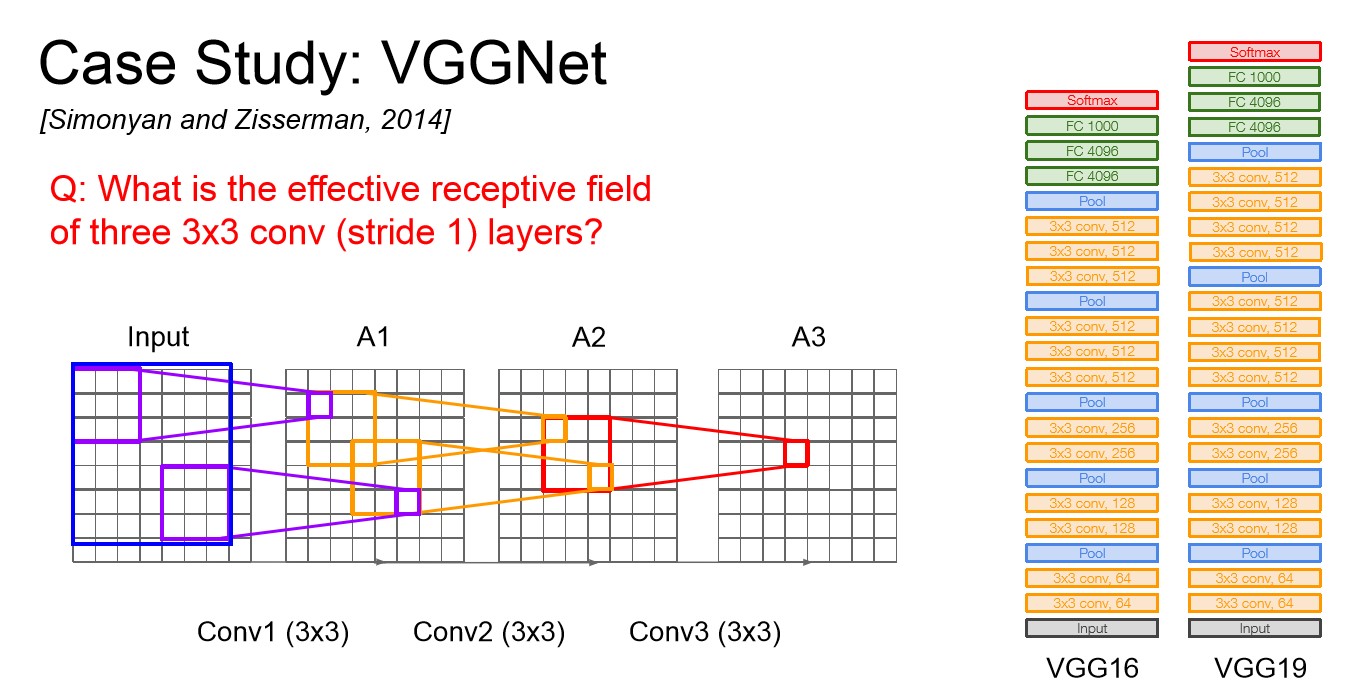 VGGNet
VGGNet
- 이전 CNN에 비해 훨씬 더 깊어졌고, 더 작은 필터를 사용한다.
- AlexNet에서는 8개의 레이어였지만 VGGNet은 16에서 19개의 레이어를 가진다.
- VGGNet은 크기가 작은 3x3 filter만을 사용한다. Filter의 크기가 작으면 파라미터 수가 작기에 큰 filter에 비해 더 많은 layer를 쌓아 Depth를 더 깊게 가져갈 수 있다.
- 위의 이미지를 보면 3x3 filter를 여러개 쓰는 것과 7x7 filter 하나를 쓰는 것의 실질적인 Receptive field가 같다는 것을 확인할 수 있다.
- 게다가 더 깊게 layer를 쌓을 수 있어 Non-Linearity가 추가되고 파라미터 수도 적어진다. 3x3의 경우 3 * 3 * C * C에 layer의 개수인 3이 곱해지고, 7x7의 경우 7 * 7 * C * C로 3x3 layer를 쓰는 것이 파라미터의 수가 확실히 적다는 것을 알 수 있다.
- Depth는 학습가능한 가중치W를 가진 layer의 수를 말한다.
- VGG19는 VGG16에 비해 조금 더 깊어 아주 조금 더 좋다. 하지만 메모리도 좀 더 쓰기에 보통 VGG16을 더 많이 사용한다.
- AlexNet과 마찬가지로 앙상블 기법을 사용했다.
- 마지막 FC layer의 경우 FC7은 4096 size의 layer인데 좋은 feature representaiton을 가지고 있고 다른 task에서도 일반화 능력이 뛰어난 것으로 알려져있다.
04.GoogleNet
GoogleNet
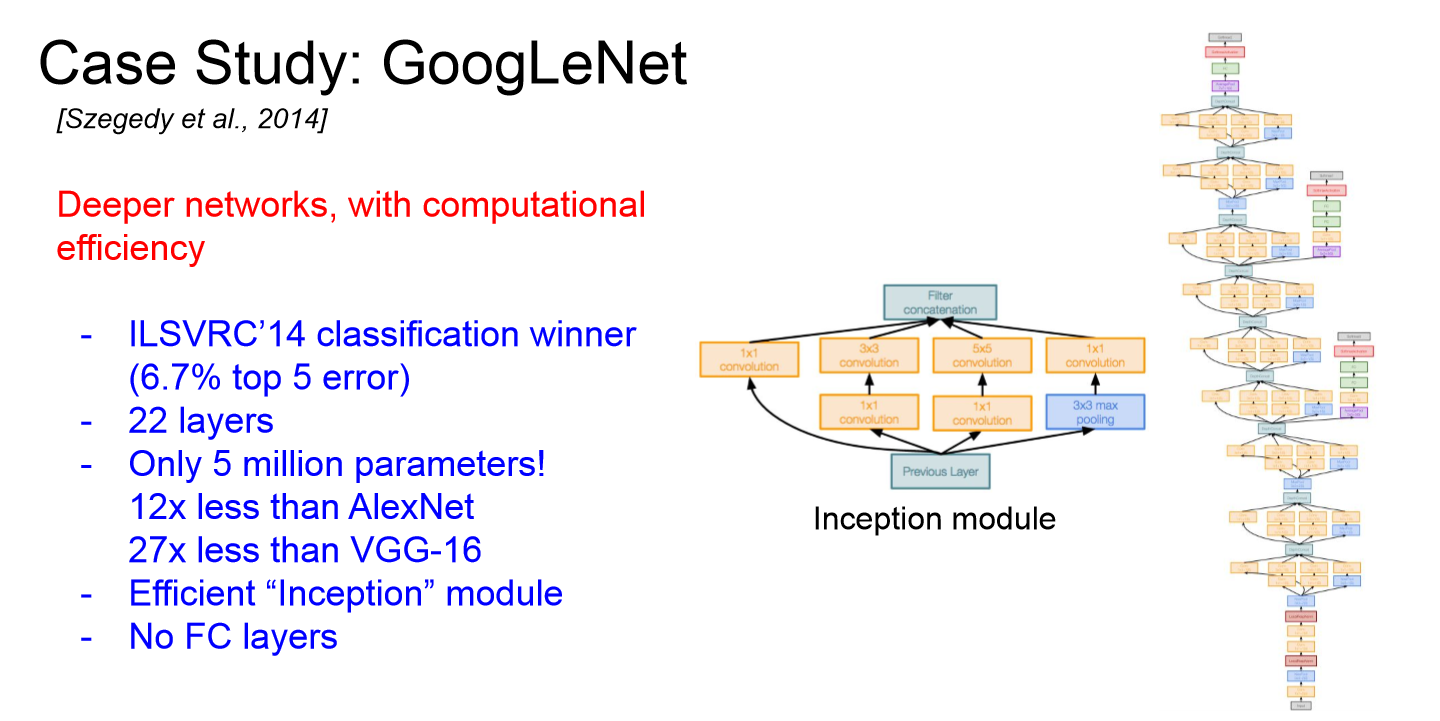 GoogleNet
GoogleNet
- 2014년 Classification Challenge에서 우승한 모델이다.
- Inception module을 통해 효율적인 계산이 가능해 layer가 많아도 적은 파라미터 수를 가져갈 수 있었다. 따라서 네트워크를 깊게 가져가면서도 효율적인 계산량을 가져갈 수 있다.
- GoogleNet의 전체 파라미터 수는 5M 정도로, 16개의 layer를 가져가는 VGGNet의 파라미터 수가 60M인 것을 감안하면 굉장히 효율적인 것을 알 수 있다.
- 또한 계산량이 많은 FC layer를 사용하지 않았다.
Inception Module
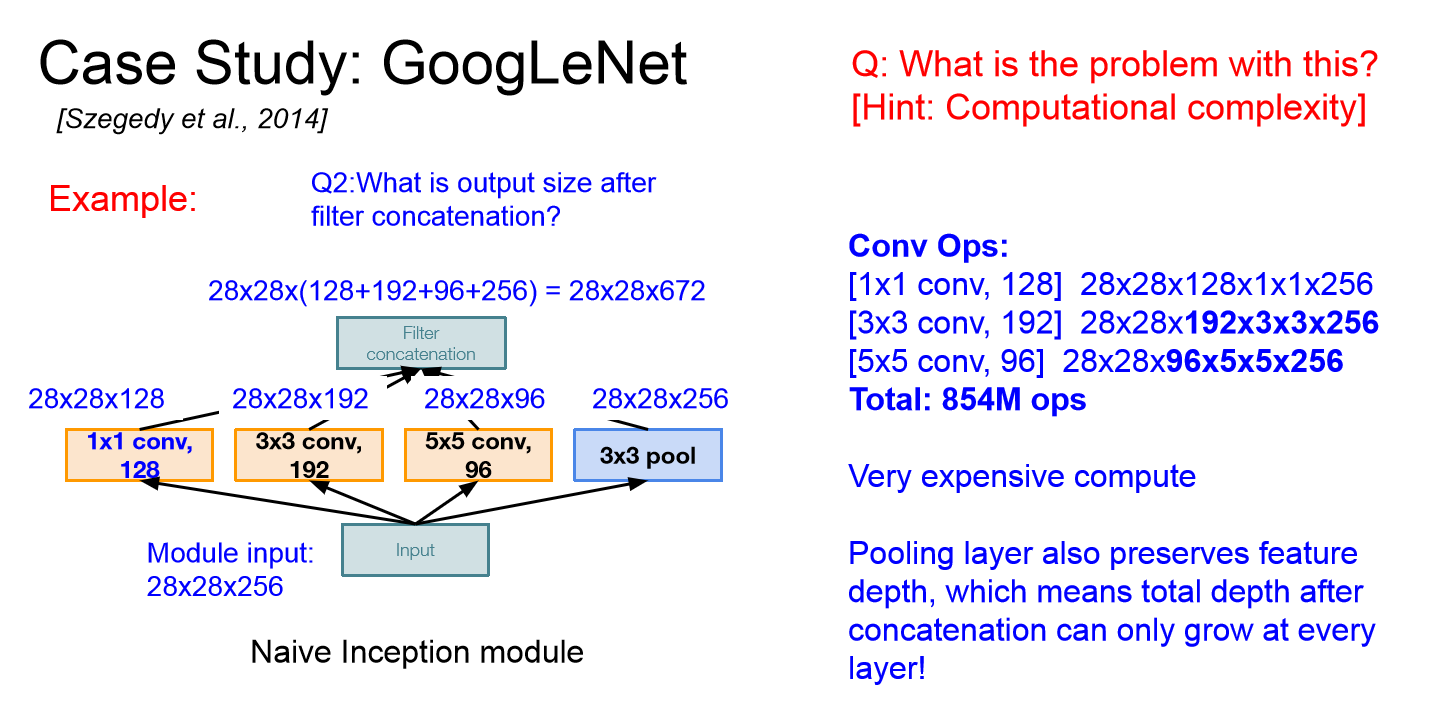 Inception Module
Inception Module
- 여러 receptive field size를 가지는 1x1, 3x3, 5x5 convolution과 3x3 pooling layer를 병렬적 filter 연산을 적용하고 output을 하나로 합친다.
- 다양한 size의 filter를 이용하여 다양한 feature를 뽑아, 보다 의미있는 feature를 뽑아낸다.
- 하지만 위의 이미지에서 확인할 수 있듯이 계산량이 너무 많아지는 문제가 있다.
Bottleneck Layer
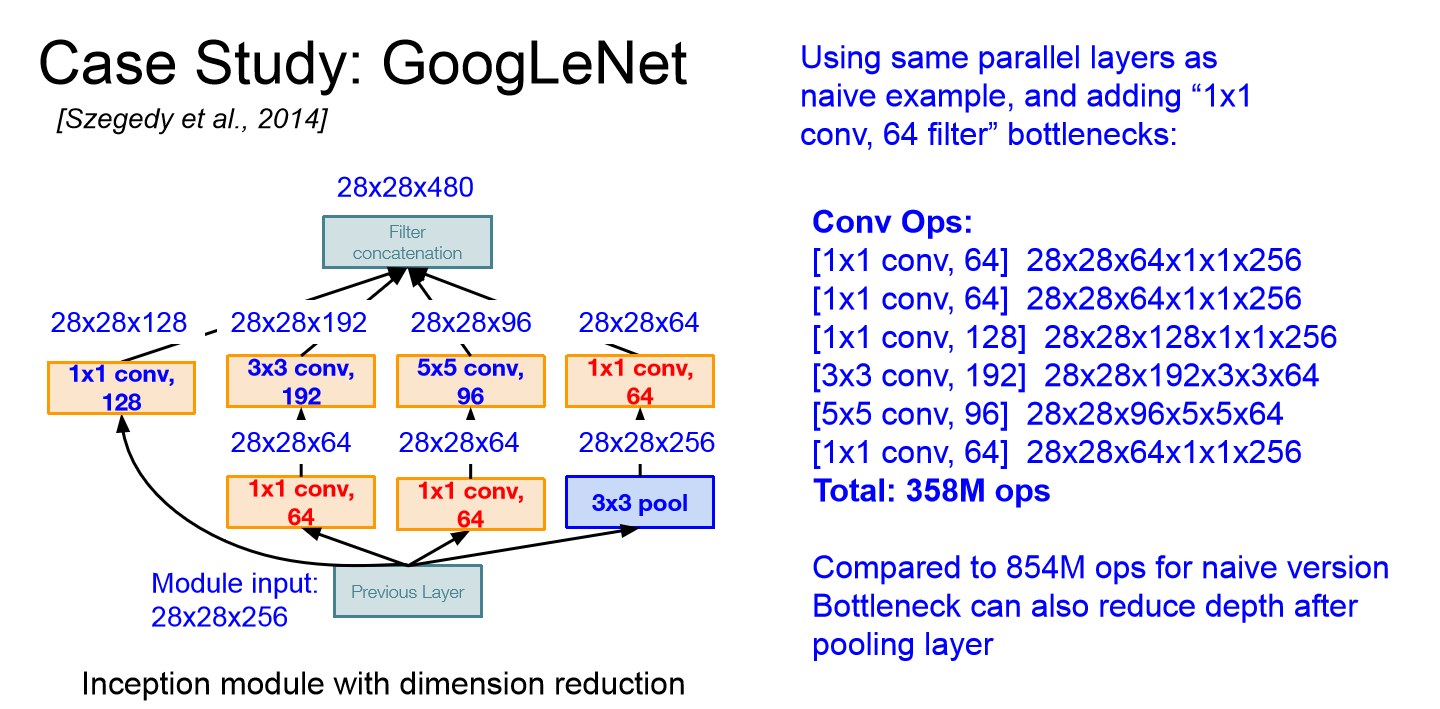 Bottleneck Layer
Bottleneck Layer
- Conv 연산을 수행하기에 앞서 1x1 convolution을 통해 channel size를 줄여 입력을 더 낮은 차원으로 보낸다.
- Bottleneck layer를 적용후 파라미터의 개수가 854M에서 358M으로 줄인 것을 확인할 수 있다.
- CNN이 너무 깊어져 생길수 있는 overffiting과 gardient vanishing의 위험을 감소시킬 수 있다.
05.ResNet
ResNet
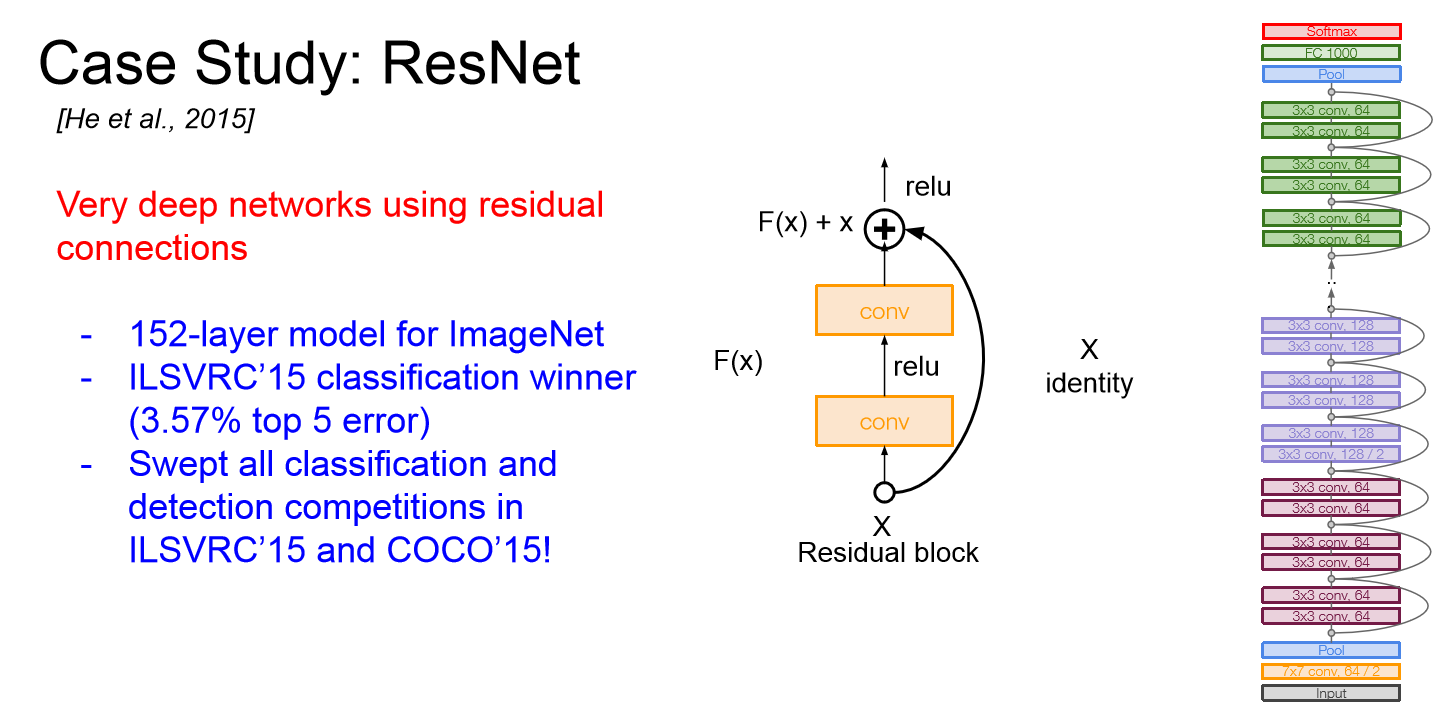 ResNet
ResNet
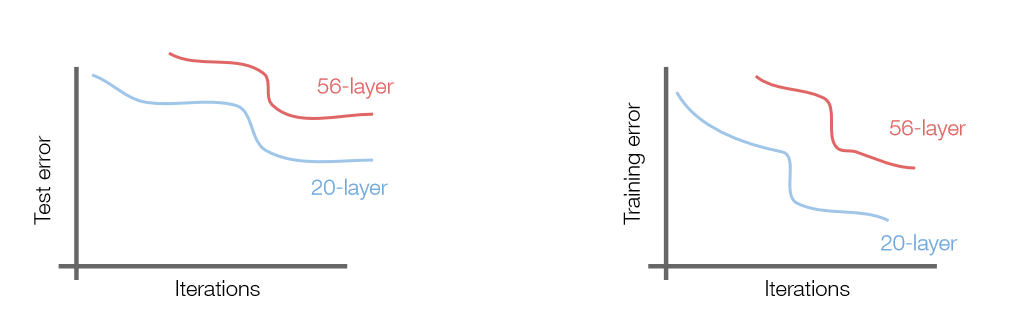 layer 증가에 따른 차이
layer 증가에 따른 차이
- ILSVRC 2015년도 우승 모델로 152 layer로 구성된 굉장히 깊은 네트워크이다.
- 보통 CNN에서 layer가 깊어지면 파라미터가 많아져서 Overffiting 때문에 성능이 안좋아질 것이라 예상하지만, training과 test에서 모두 성능이 안좋아지는 것을 확인했다. 이는 Overffiting 때문이 아니라는 것을 말하기에, 더 깊은 모델 학습시 optimization 문제가 생긴다는 가설을 설정한다.
- 그 해결책으로 적어도 얕은 모델만큼의 성능을 내기 위해 더 얕은 모델의 가중치를 깊은 모델의 일부 레이어에 복사하는 해결책으로 나온 것이 Residual block이다.
Residual Block
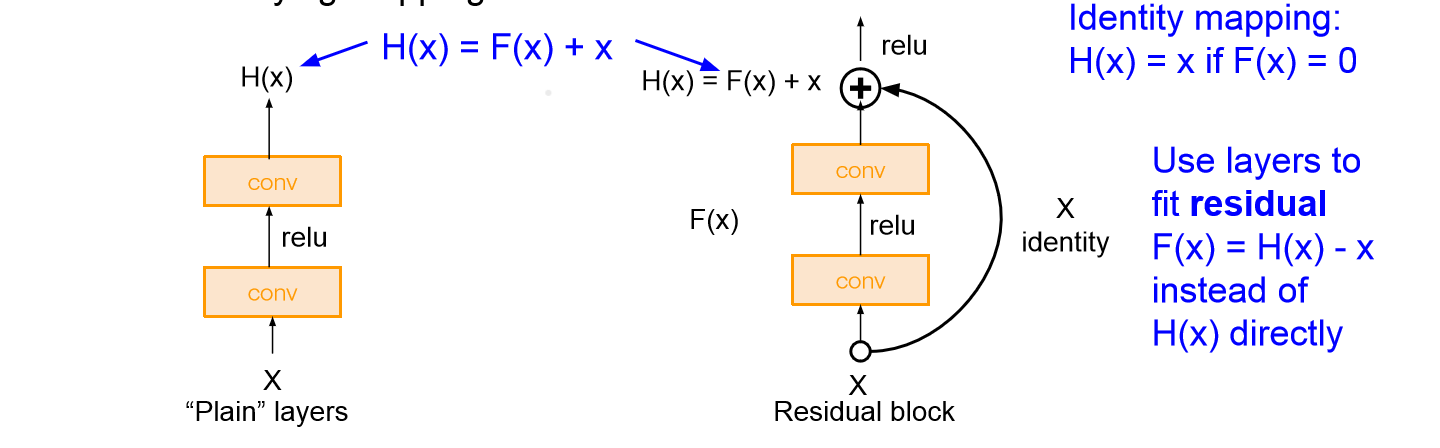 Residual Block
Residual Block
- Skip connection을 통해 입력을 출력단으로 보내 H(x)를 학습한다기 보다는 H(x)-x를 학습할 수 있도록 만들어준다. 이를 통해 학습을 방해하는 층이 있어도 학습이 가능하다.
- Gradient를 계산해보면 residual block의 경우 H’(x)-1로 H’(x)=0이 되어도 학습이 가능하다. 따라서 gradient vanishing 같은 문제를 해결할 수 있어 보다 깊게 신경망을 구성할 수 있다.
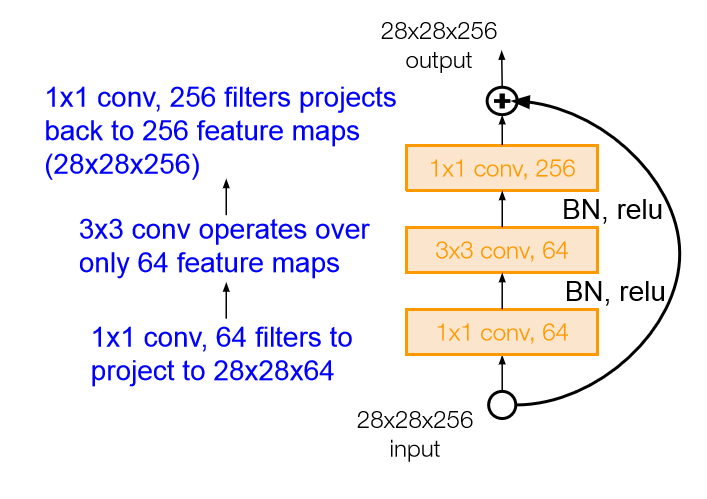 Residual Block with Bottleneck layer
Residual Block with Bottleneck layer - 또한 GoogleNet과 같이 1x1 convolution을 통한 bottleneck layer를 사용해 효율적으로 깊은 layer를 구성할 수 있도록 해주었다.
ResNet 특징
- 모든 Conovlution layer 뒤에 Batch Normalization을 적용했다.
- Xavir initialization 적용
- SGD + Momentum: 0.9
- Learning rate: 0.1
- Mini-batch size 256
- Weight decay 1e-5
- Dropout X
06.Improving ResNet
- ResNet을 차용해 성능을 높인 신경망들이 있다. 간단하게만 알아보고 넘어간다.
Good Practices for Deep Feature Fusion
SENet(Squeeze-and-Excitation Networks
Identity Mapping in Deep Residual Network
Wide Residual Networks
ResNeXt(Aggregated Residual Transforamtions for Deep Neural Networks
DenseNet(Densely Connected Convolutional Networks
MobileNets: Efficient Convolutional Neural Networks for Mobile Applicaiton
NASNet(Neural Architecture Search with Reinforcement Learning)
Learning Transferable Architectures for Scaleable Image Recognition
EfficientNet: Smart Compund Scaling
3. Transfer Learning
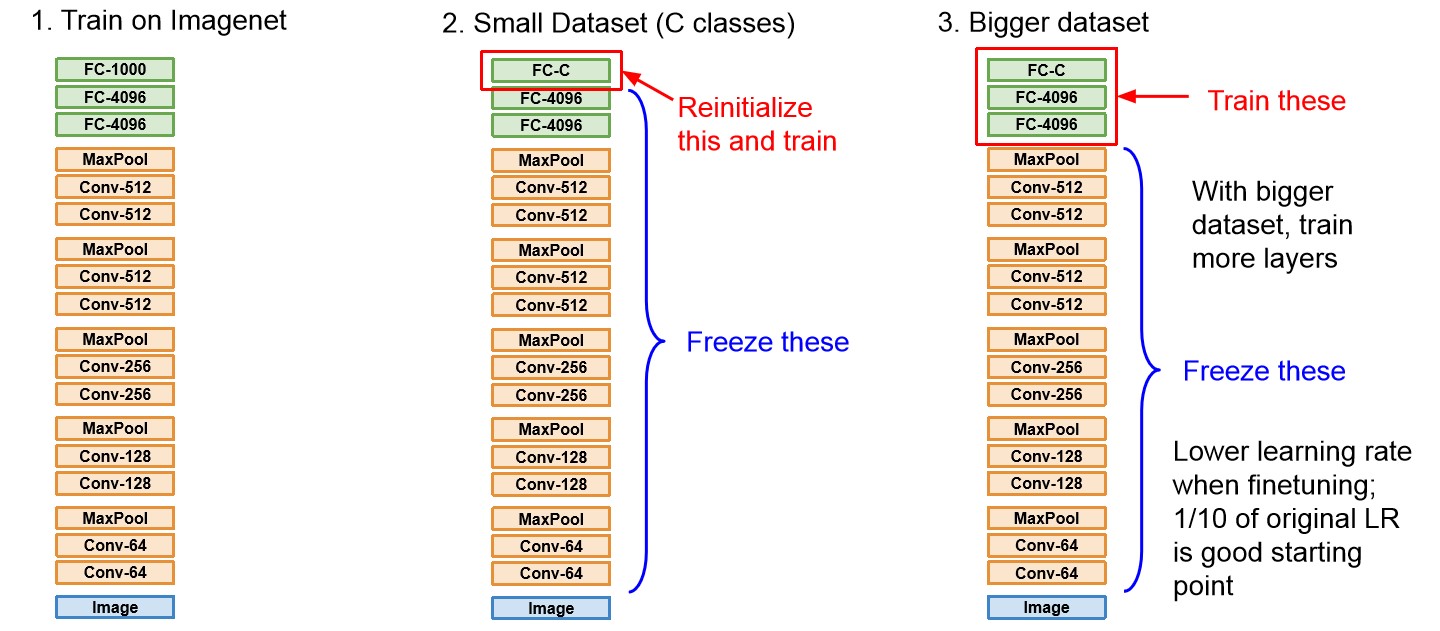
- Transfer learning은 모델학습을 위한 데이터가 적을 때, 사전 학습된 모델(pre-trained model)을 이용하여 학습하는 것을 말한다.
- Pre-trained model을 이용함으로서 입력 데이터의 특징 추출을 위한 학습을 별도로 하지 않아도 되기에 빠르게 학습을 수행할 수 있고, 데이터셋이 적을 때의 Overffiting을 예방할 수 있다.
- 다만 transfer learning을 잘 하기 위해서는 사전학습한 데이터와 새로운 데이터가 비슷한 형태여야 하고, 새로운 데이터보다 많은 데이터로 사전학습이 수행되었어야 한다.
- 보통 ImageNet으로 학습시킨 CNN 구조를 그대로 두고 FC layer를 새로 학습시킨다.
- 새로운 train 데이터의 양에 따라 학습시킬 FC layer의 양을 조절한다.
- 또한 동일한 조건에서 바닥부터 학습시키는 것보다 2~3배 빠르게 학습할 수 있다고 한다.
소단원
Keyword

- 내용 정리
-
특징
Summary
개인 공부 기록용 블로그 입니다.