
[CS231] Lec7. Training Neural Networks
📢Key Words: Relu, Zero-centered data, Drop out Activation function과 신경망 학습에 쓰이는 각종 기법들에 대해 알아본다.
1. Activation Function
- Activation function(활성 함수)은 신경망 회로에서, 한 노드에 대한 입력값을 다음 노드에 보낼지 말지에 대해 결정하는 함수이다.
- 비선형 함수로 구성이 되는데, 선형함수를 사용할 시 층을 깊게하는 의미가 없어지기 때문이다.
- 예를들어 $h(x)=cx$를 활성함수로 사용한 3층 네트워크가 있으면 이는 $y(x)=h(h(h(x)))$가 된다. 그런데 이는 $a=c^3$인 y(x)=ax, 1층의 네트워크로 표현이 가능하기에 은닉층을 쌓은 이유가 없어진다. 따라서 딥러닝에서 비선형함수를 활성함수로 사용한다.
01. Sigmoid
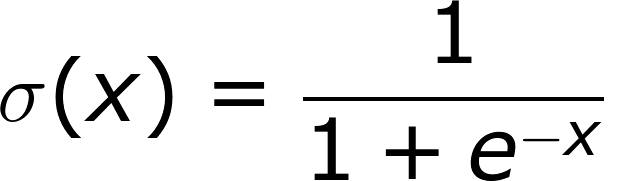 Sigmoid
Sigmoid
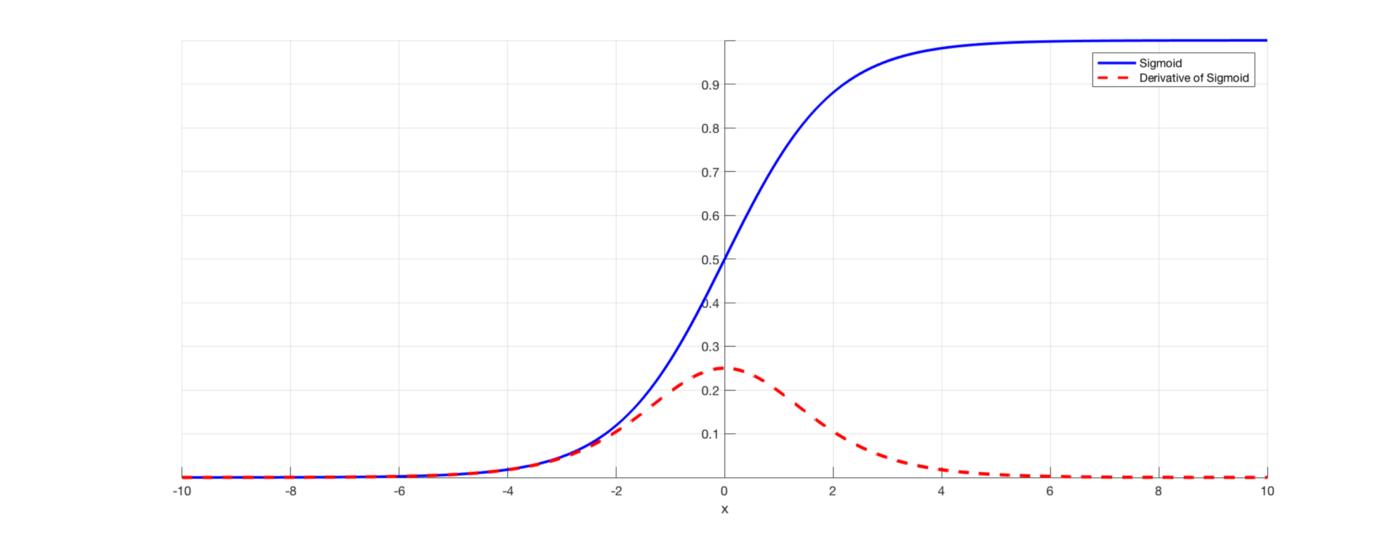 Sigmoid Funtion Graph
Sigmoid Funtion Graph
- Sigmoid 함수는 Input을 [0,1]사이의 값이 되도록 해준다.
- Sigmoid가 뉴련의 fireing rate를 saturation 시키는 것으로 해석이 가능해 역사적으로 많이 쓰였다.fireing rate는 어떠한 값이 [0,1] 사이의 값을 가지는 것을 말한다.
- 하지만 sigmoid는 몇가지 문제 때문에 더이상 activation function으로 쓰이지 않는다.
- 먼저 gradinet vanishing 때문이다. 위 그래프에서 미분함수 그래프를 보면 gradient가 0에 가까워지는 saturation 현상을 확인할 수 있다. 이로 인해 gradient가 죽어버리고 더이상 가중치 W가 업데이트 되지 않아 학습이 진행되지 않는다.
- 다음으로 sigmoid의 출력이 zero-centered 하지 않기 때문이다.
- 보충
02. tanh
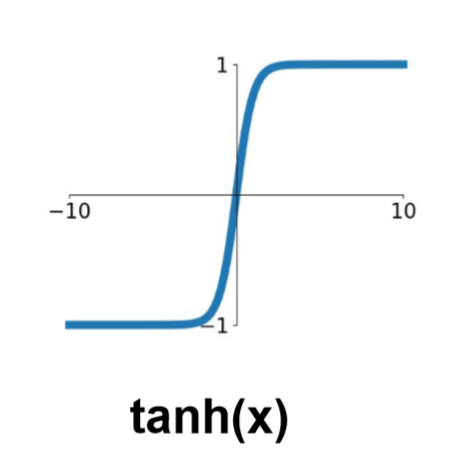 tanh
tanh
- tanh 함수는 Inputdmf [-1,1] 사이의 값이 되도록 해준다.
- Sigmoid와 달리 output이 zero-centered한 장점이 있다.
- 하지만 여전히 saturation 문제가 있기에 tanh 역시 activation function으로 사용하지 않는다.
03. ReLu
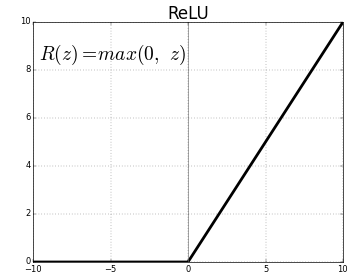 ReLu
ReLu
- Relu함수는 input이 0이하면 모두 0으로 보내고 0보다 크면 그대로 보낸다. 선형함수의 요소가 있지만 엄연함 비선형 함수이기에 activation function으로 사용할 수 있다.
- 지수함수로 구성된 sigmoid와 달리 선형함수로 구성되기에 계산량이 적기에 가중치를 빠르게 업데이트 할 수 있다.. tanh보다 6배 가량 빠르다고 한다.
- 또한 양의 값에서 saturation 하지 않기에 gradient vanishing의 문제가 없다.
- 하지만 Relu 역시 zero-centered하지 않고, 음수에서는 saturation 하는 문제가 있다.
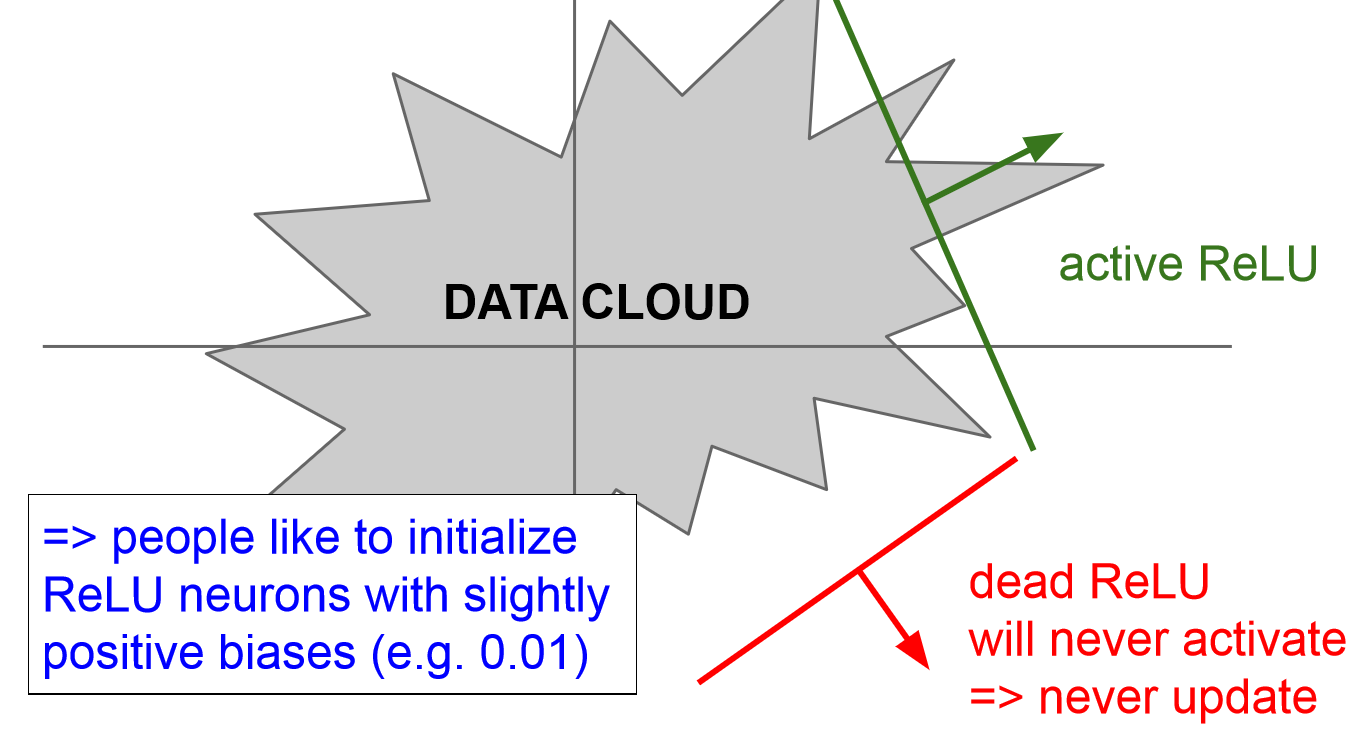 Dead Relu
Dead Relu - 또한 Dead Relu 문제가 있다. Relu는 기본적으로 절반의 데이터를 죽여버리는데, 이를 잘못 초기화할 경우 어떤 입력에도 ReLu가 activation하지 않는 문제가 생길 수 있다.
- 더 흔하게 문제되는 원인으로 learning rate를 너무 크게 설정했을 경우이다. 이 경우 weight update가 지나치게 커지면 W가 날뛰면서 ReLu가 data의 영역을 벗어나게 된다고 한다.
- 따라서 이를 해결하기 위해 아주 작은 positive bias를 이용해 초기화 하기도 한다고 한다.
- Activation function으로 가장 일반적이게 많이 쓰인다고 한다.
04. Leaky ReLu
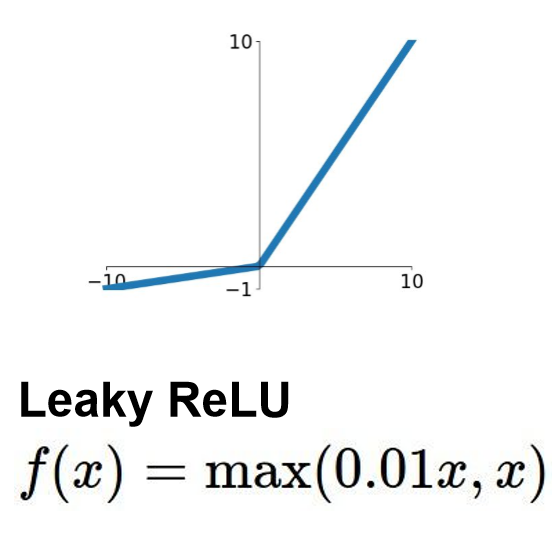 Leaky Relu
Leaky Relu
- Leaky ReLu는 input이 음수인 경우 0이 아니라 $0.01x$ 값을 출력시켜 ReLu의 문제를 보완한 activation function이다.
- 따라서 saturated하지 않고 Dead Relu 현상도 없게 된다.
- 0.01x대신 $ax$를 출력시키는 PReLu(Parametric Rectifier)도 있다. 이때 알파는 backprop를 통해 학습시키는 파라미터이다.
05. ELU (Exponential Linear Units)
 ELU
ELU
- ELU는 지수함수를 통해 0에서도 미분가능하도록 하여 output이 보다 zero-centered 하도록 보완한 함수이다.
- 하지만 exp()가 들어가기에 계산량이 많아지는 단점이 있다.
- 또한 음수에서 saturation하게 되는데, 이것이 noise에 좀 더 강인할 수 있다고 한다.
06. SELU (Scaled Exponential Linear Units)
 SELU
SELU
- SELU는
07. Maxout “Neuron”
MAxout
- Maxout은 입력을 받아들이는 특정한 기본 형식을 미리 정의하지 않는다.
- Maxout은 두 개의 선형 함수를 취하기에 ReLU와 Leaky ReLU의 좀 더 일반화된 형태이다.
- Maxout도 선형함수로 이루어져 있기에 saturation하지 않고 Dead ReLu 현상도 없다. 하지만 뉴런당 파라미터의 수가 w1 w2로 2배가 되기에 계산량이 많아진다.
2. Data Preprocessing
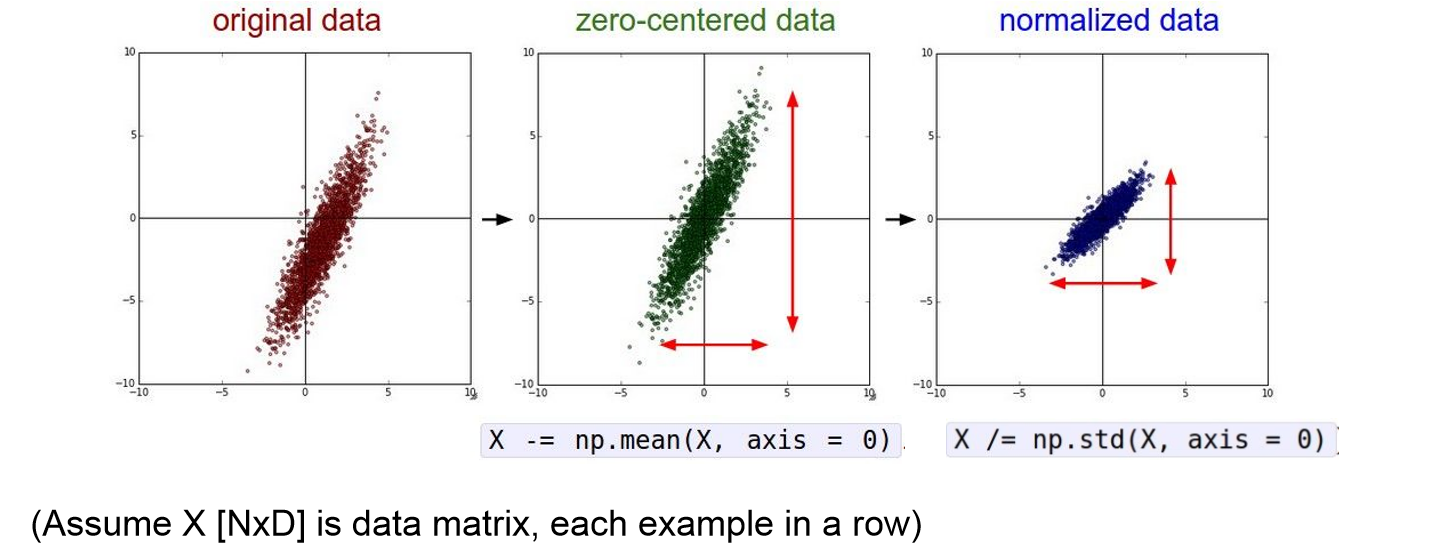
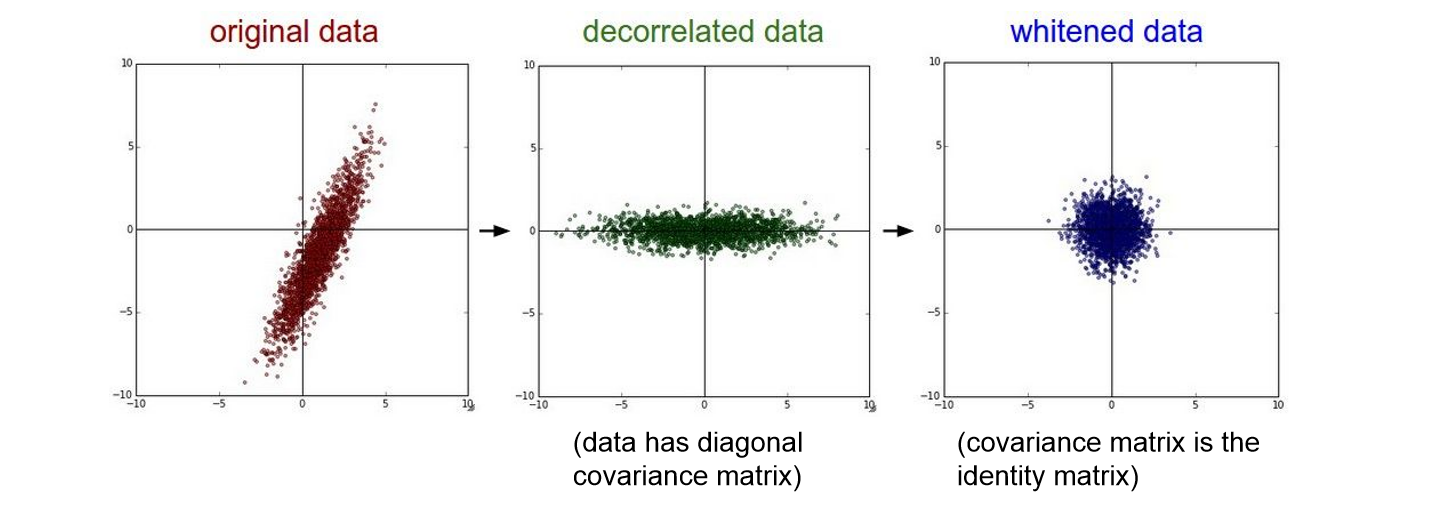 Data Preprocessing
Data Preprocessing
- 일반적으로 input data는 전처리를 해준다. 대표적으로 ‘zero-centerd’해주는 것과 ‘normalize’해주는 것이다.
- Data를 zero-centered하게 만들어주어 입력값이 양수나 음수에 치우쳐 학습시 zigzag하는 문제를 보완해준다.
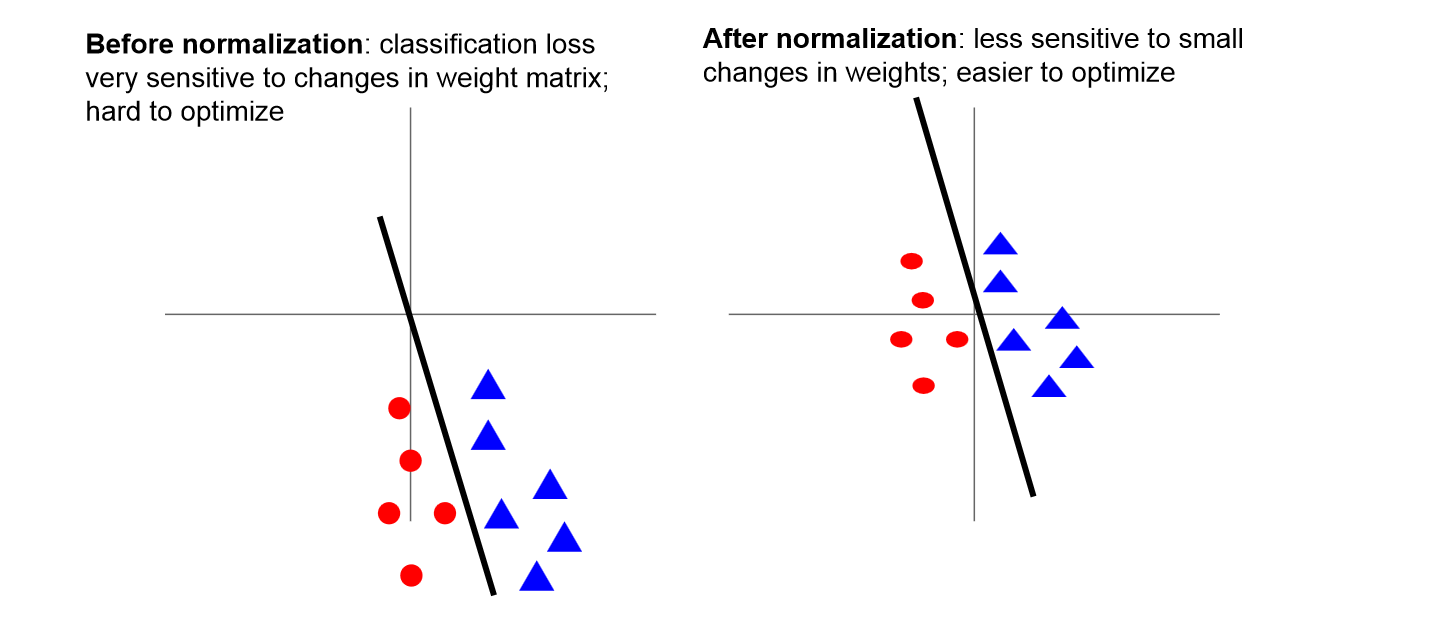
- Normalization을 통해 데이터들이 동등하게 기여할 수 있도록 해주고, classification loss에 있어서 덜 sensitive하게 해준다.
- 하지만 Image에서는 zero-center만 적용해준다고 한다. 전처리에서 normalize를 해줄시 이미지 원본의 공간적인 의미가 퇴색될 수 있기 때문이다.
- PCA나 whitening도 있지만 잘 사용하지 않는다고 한다.
3. Weight Initialization
- W를 모두 같은 0으로 초기화 한다면, 모든 뉴런의 gradient가 같을 것이고 똑같이 업데이트되는 문제가 생긴다.
- 이를 보완하기위한 방법들이 있다.
01. Small Random Numbers
 Small Random Number
Small Random Number - 먼저, 0에 가까운 아주 작은 랜덤의 값으로 W를 초기화 해주는 방법이다.
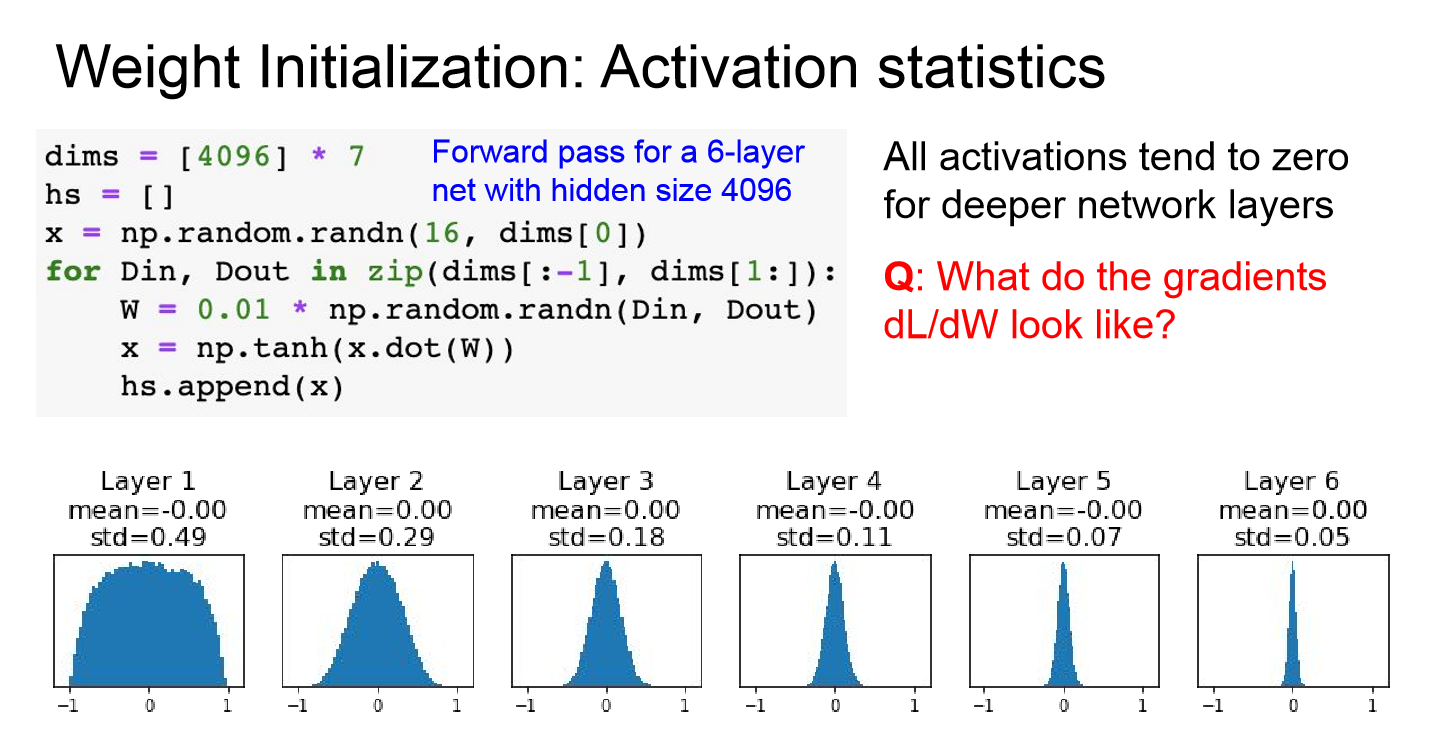 Layer 별 Activation 수치
Layer 별 Activation 수치
- 하지만 위 그래프를 보면 알 수 있듯이 뉴런의 입력값이 너무 작아 backpropagation 단계에서 local gradient가 0에 가까워져 가중치 업데이트가 진행되지 않고 학습이 진행되지 않게 되는 문제가 생긴다.
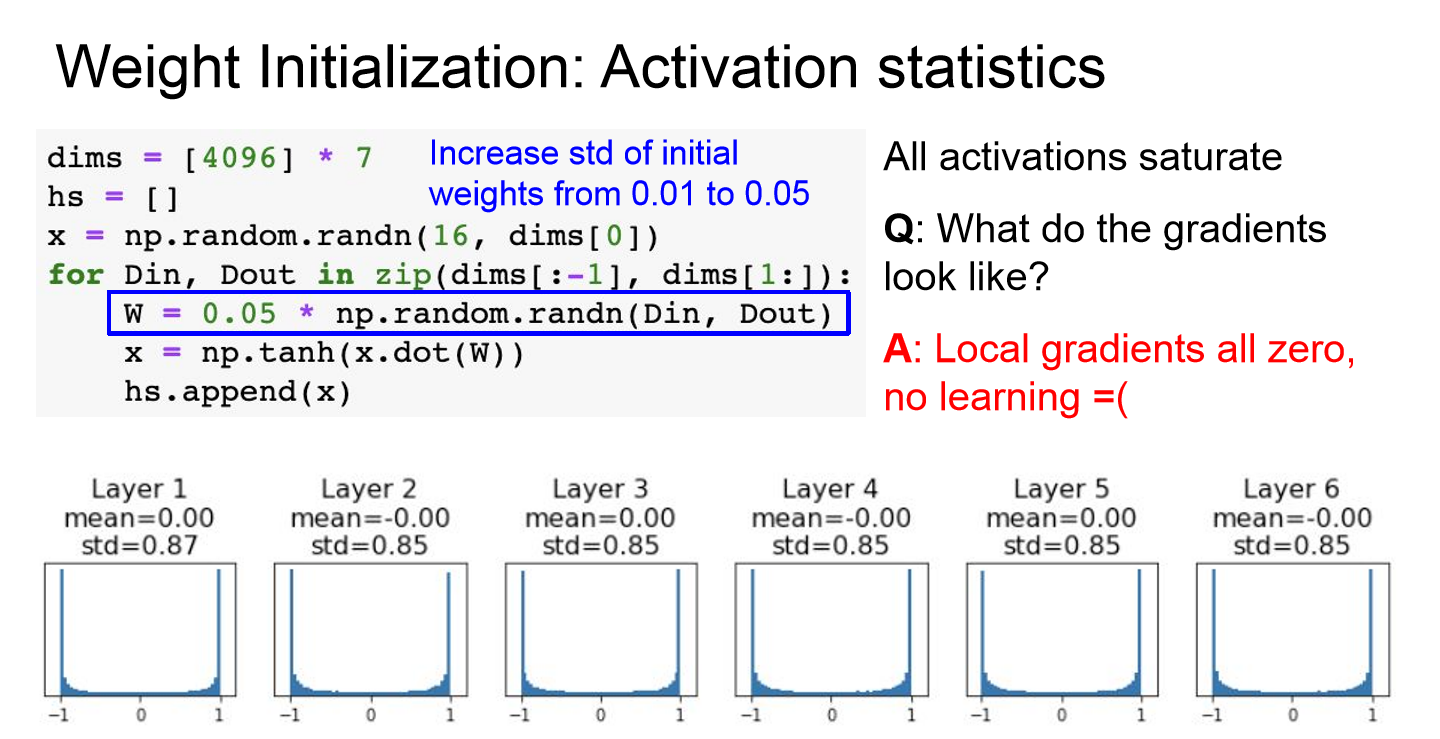
- 그렇다고 W는 큰 값으로 초기화해준다면 tanh를 예로 들면 saturation하게 되고 gradient가 0이 되는 문제가 생긴다.
- 이처럼 적잘한 가중치로 업데이트 하는 것이 어렵기에 나온 방법이 Xavier Initializaiton이다.
02. Xavier Initialization
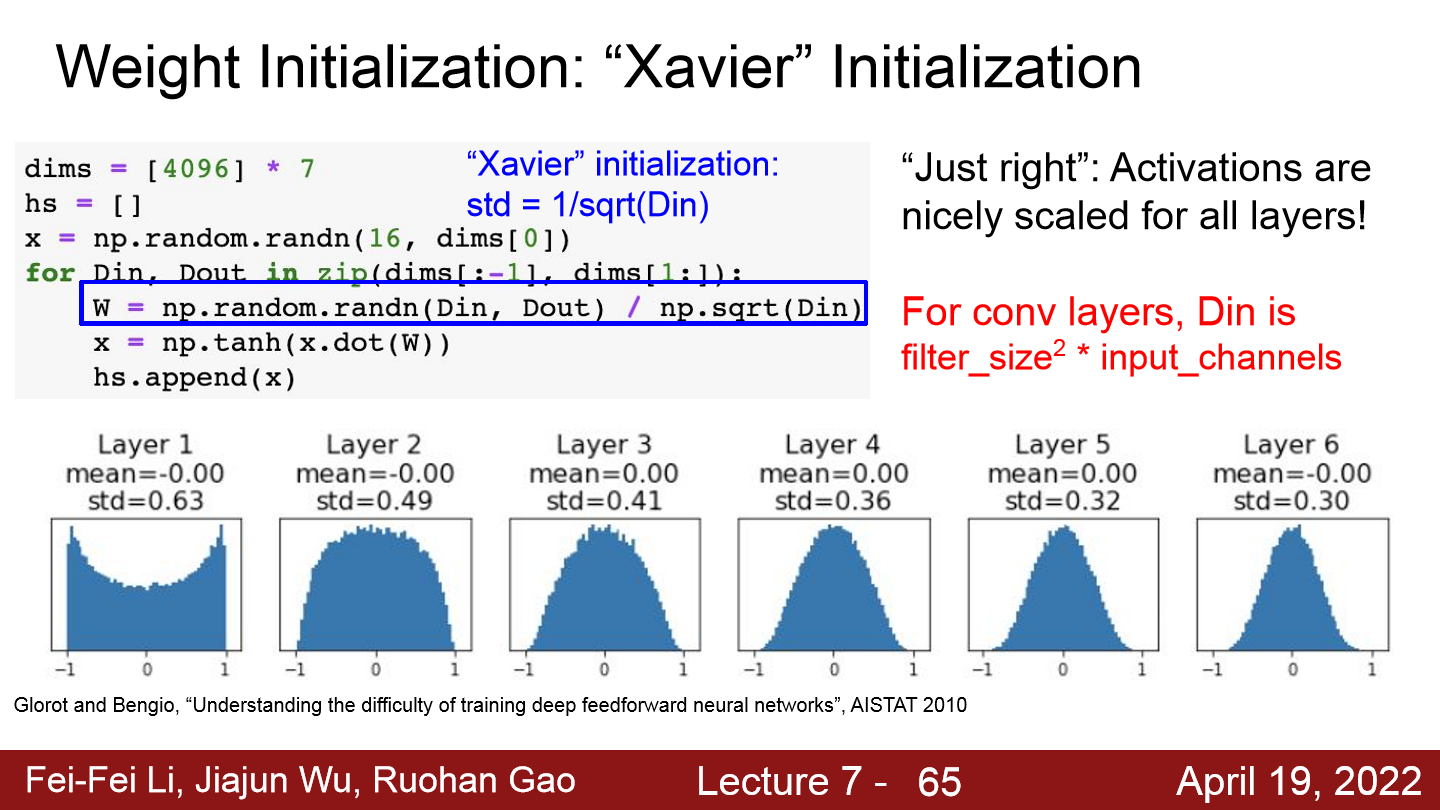 Xavier initialization
Xavier initialization
- Xavier initialization은 Standard gaussian으로 뽑은 값을 ‘입력의 수’로 스케일링해준다. 입력의 수적으면 작게 나눠 상대적으로 좀 더 큰 값을 얻는다. 이는 입/출력의 분산을 맞춰주는 역할을 하게 된다.

- 그런데 위의 그래프를 통해 이를 확인할 수 있듯이, Xavier initializaiton은 선형의 zero-centered activation function을 가정한 것이기에 ReLu를 사용하면 데이터의 반이 날아가 결국 gradient가 다시 0으로 수렴하게 된다.
03. Kaiming / MSRA Initialization
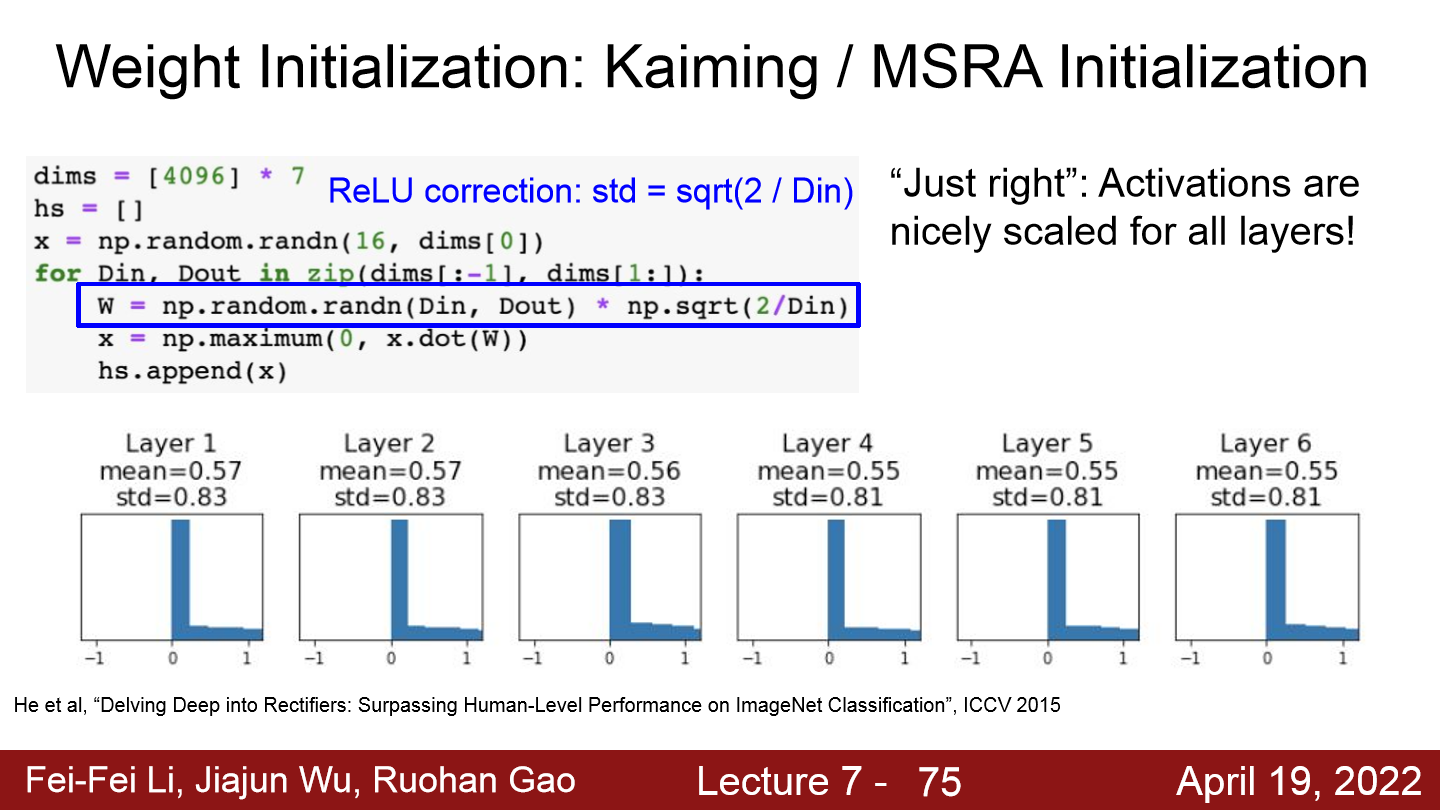
- Xavier initialization이 ReLu에서 제대로 학습이 진행되지 않는 문제를 해결하기위해 ReLu는 입력값의 절반이 없어지는걸 감안하여 수식에 추가적으로 $/2$를 적용한 것이 Kaiming / MSRA Initialization이다.
- 위 그래프를 보면 모든 layer에서 activaiton값이 잘 분포 돼 있는 것을 확인할 수 있다.
4. Training vs Testing Error
- 좋은 optimization은 ‘training loss’를 줄이는데에 도움을 준다. 우리는 ‘test loss’를 줄이는 것이 목표인데 trainig에서와 test에서의 loss가 차이있는 Overfitting이 발생하는 경우가 있다.
- 따라서 training과 test의 loss 차이를 줄이는 방법을 알아본다.
01. Early Stopping
Early Stopping
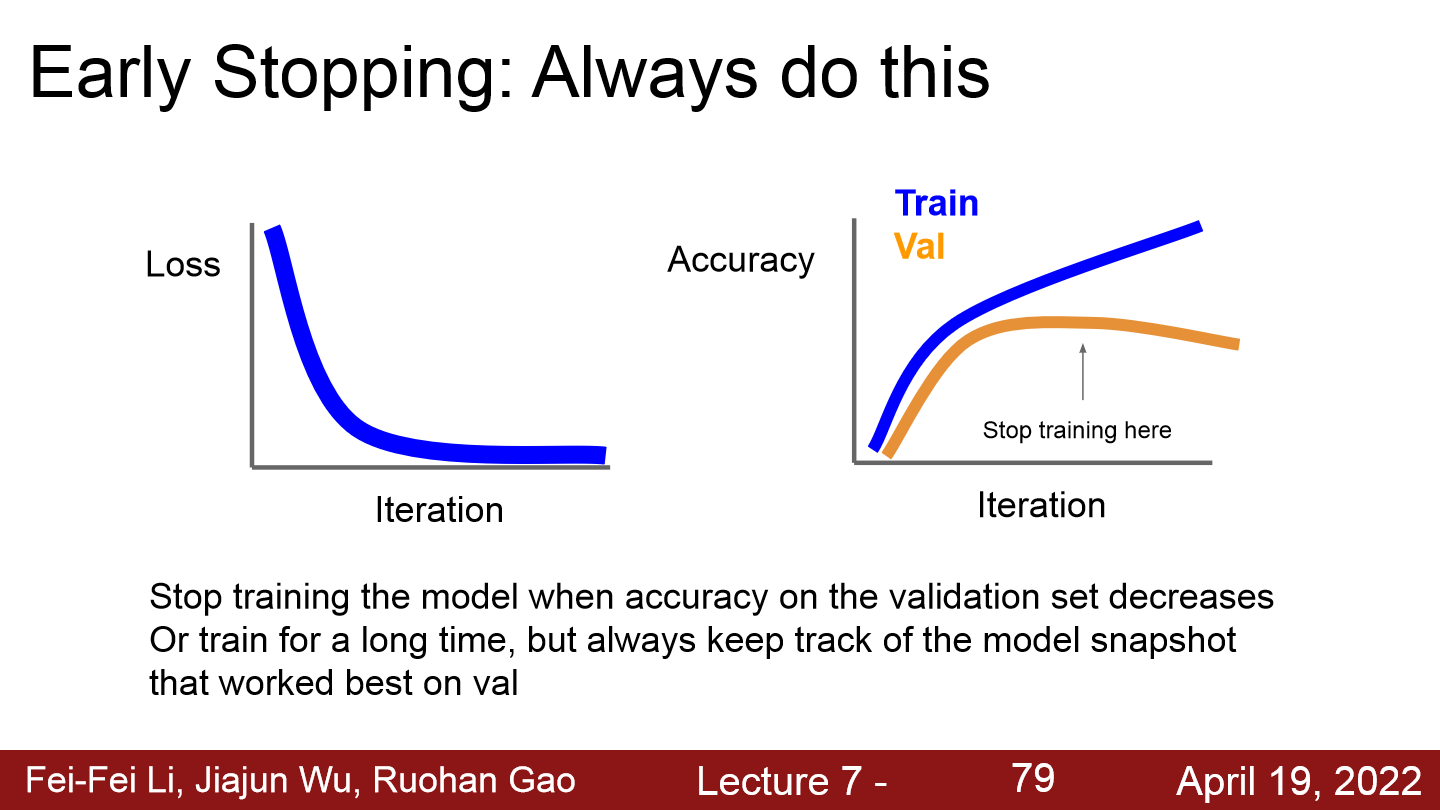
- Early Stopping은 validation set에서의 정확도가 낮아질 때 모델 훈련을 멈추는 것이다.
- 하지만 항상 모델을 추적하며 validation이 최고 값을 냈을 때를 포착해야한다.
02. Model Ensembles
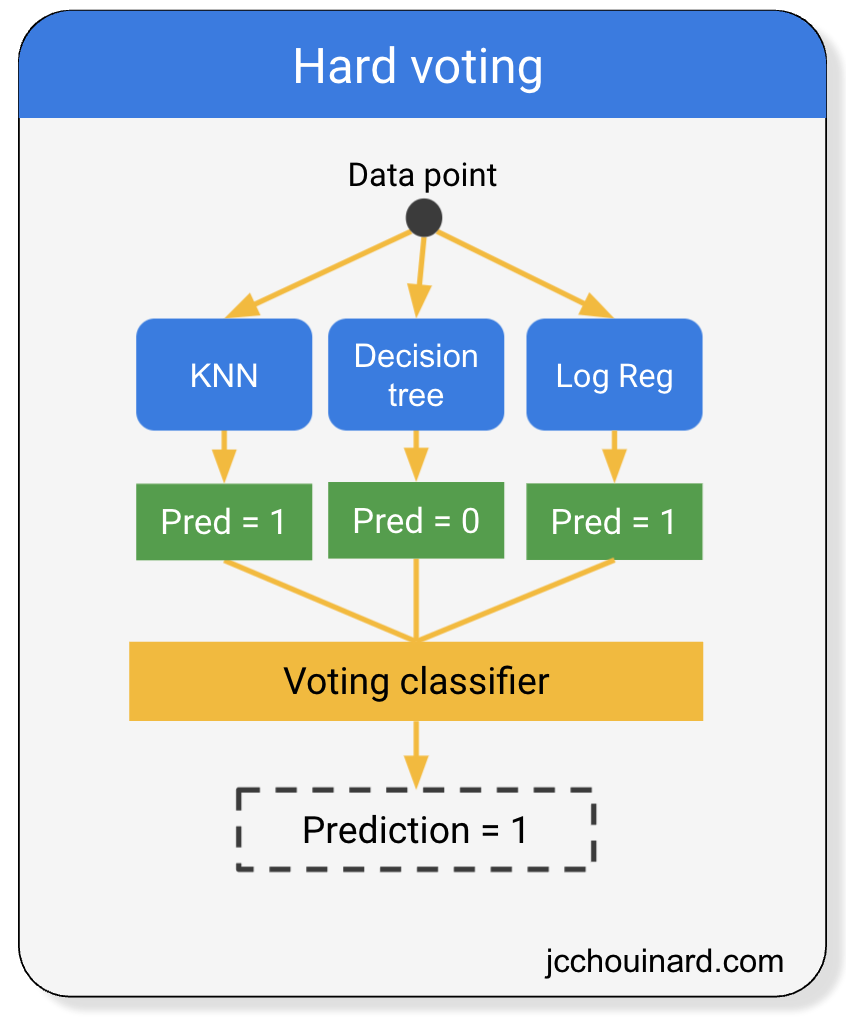
- Model Ensembles(모델 앙상블)은 여러개의 독립적인 모델을 학습시키고 test 때 투표를 통해 이들의 결과를 평균내는 것이다.
- 대략 2% 정도의 성능향상이 있다고 한다.
03. Regularization
- 그렇다면 single-model일 때 성능을 높이는 방법이 무엇인지 알아본다.
Loss Term
 Loss Term
Loss Term - 먼저 Loss항을 추가해주는 것이다.
- 보통 L2, L2 regularization나 L1 L2가 합쳐진 Elastic net을 사용한다
Dropout
 Dropout
Dropout - Dropout은 랜덤하게 각가의 neuron의 값을 0으로 만들어주는 것이다. 보통 확률 값으로 0.5를 쓴다.
- 이를 통해 신경망을 강인하게 만들어 특정 feature만 가중치가 커지며 과도하게 학습하는 Overffiting 방지한다. 예를 들어 고양이의 꼬리를 포착하는 가중치가 강력하면 꼬리의 스코어가 높아 꼬리가 가려져 있는 고양이 같은 데이터들을 분류하는데에 어려움을 겪을 것이다.
- 또한 각각의 노드를 하나의 모델로 보면 편향되지 않게하는 부분에서 큰 esenble를 훈련시키는 것과 비슷하다.
- Trainging에서의 activation의 기댓값은 활성화 되지 않은 노드 또한 셈을하여 기댓값을 계산하기에 모든 노드를 activation 했을 때의 activation 기댓값 과는 차이가 생긴다. Test에서는 모든 뉴런을 activation 해야하기에 activation에 P를 곱해줘 scale해준다.
Data Augementation
 Data Augmentation
Data Augmentation
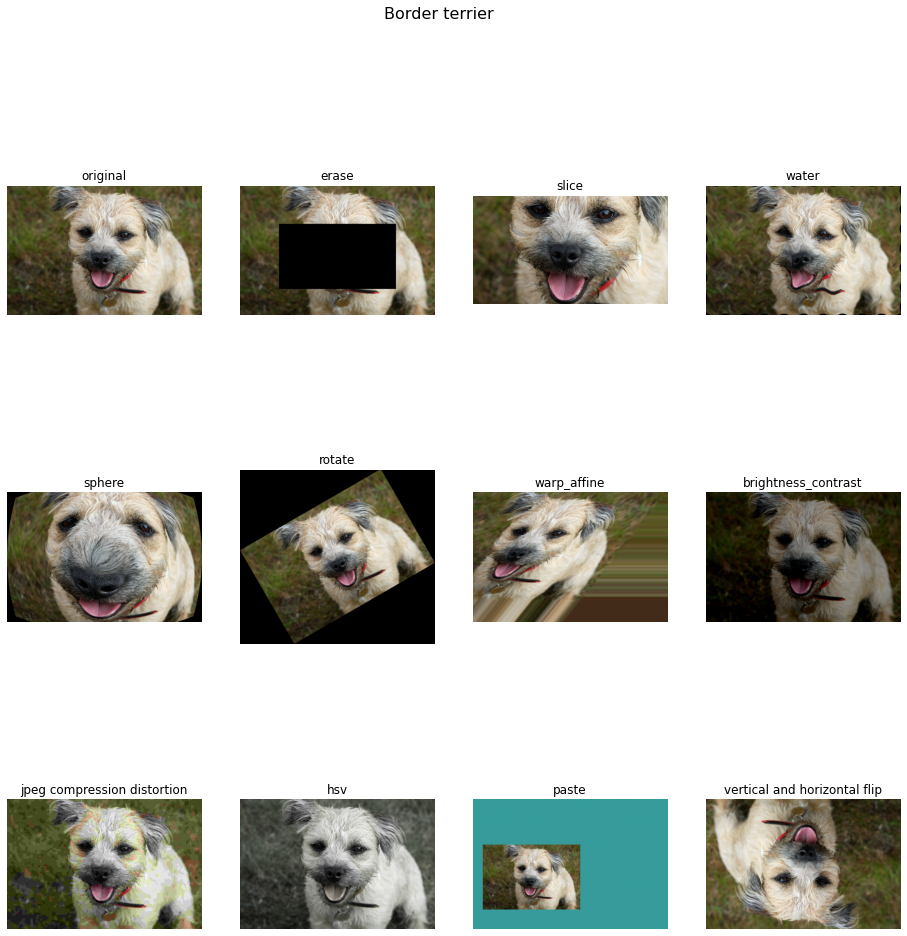
- 다음은 Data Augmentation을 통해 data의 양을 늘려주어 overfitting을 방지하는 것이다.
- Data augmentation기법으로는 Horizontal Flips, Random crops and scales, Color jitter, translation, rotation..등이 있다.
Drop Connect
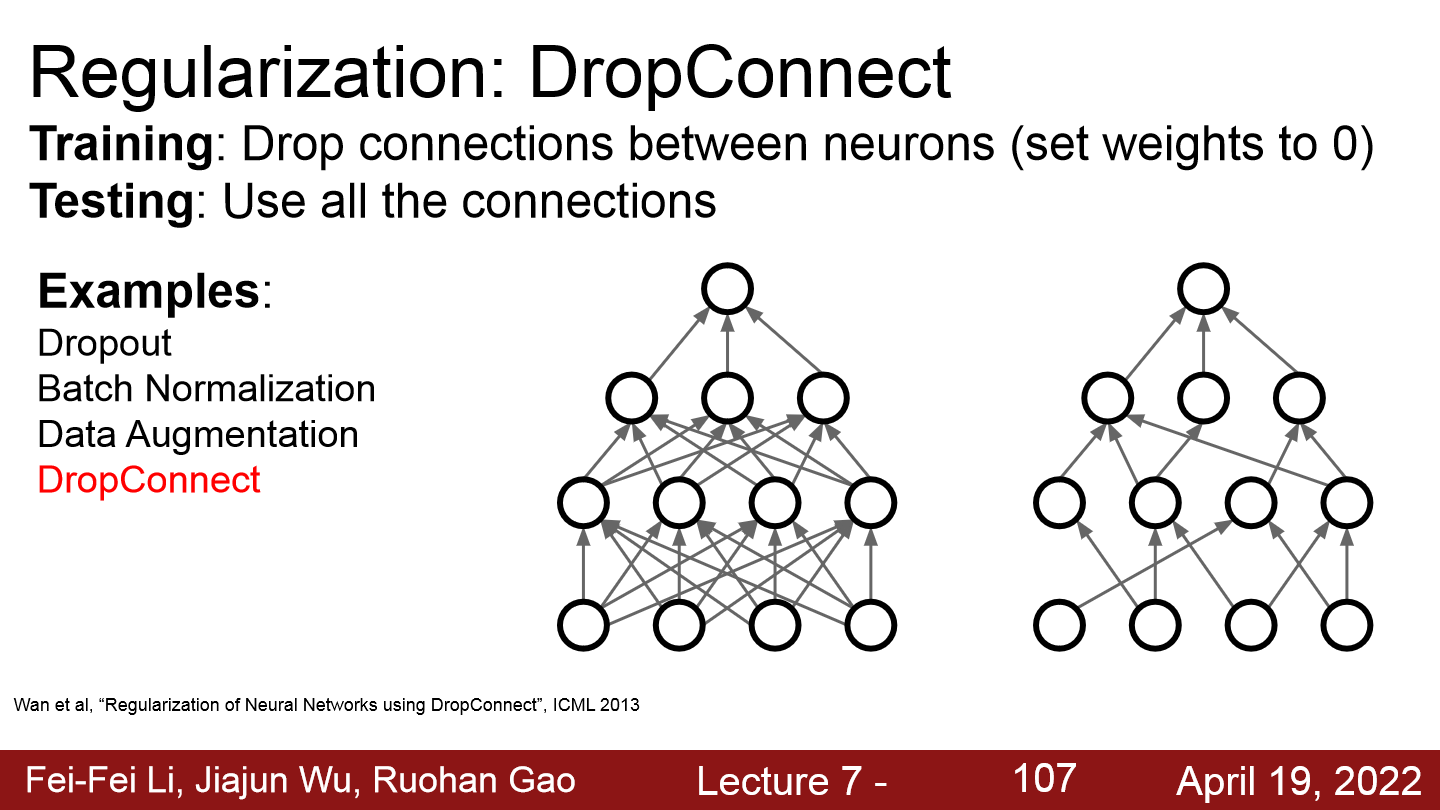 Drop Connect
Drop Connect
- Drop Connect는 Dropout을 변형시킨 것으로 노드가 아닌 가중치W를 0으로 하는 것이다.
- Drop out보다 좀 더 일반화가 되었고, 소폭의 성능향상이 있다고 한다.
Fractional Pooling
 Fractional Pooling
Fractional Pooling
- pooling할 지역을 랜덤하게 정하는 것이다.
Stochastic Depth
Stochastic Depth
- 신경망의 layer를 확률적으로 skip시킨다.
Cutout
 Cutout
Cutout
- 이미지의 일부 지역을 랜덤하게 0으로 만든다.
- CIFAR같이 Data가 적을 때만 꽤나 효과가 있다고 한다.
Mixup
 Mixup
Mixup
- 두개의 data를 랜덤한 비율의 선명도로 섞는다.
5. Choosing Hyperparameters
01. Steps of Choosing Hyperparameters
 Steps of Choosing Hyperparameters
Steps of Choosing Hyperparameters
Step 1: Check initial loss \
- Wight decay를 끄고, 첫 iteration의 loss를 확인한다. e.g. softmax의 경우 log(C)가 출력돼야한다.
- 이를 통해 모델이 제대로 구성됐는지 검사한다.
Step 2: Overfit a small sample
- 적은 양의 data를 통해 모델을 100%의 training accuracy가 나오도록 overffiting 시킨다.
- loss가 내려가지 않으면 LR가 너무 낮고 initialization이 제대로 되지 않은 것이다.
- loss가 무한으로 증가하거나 NaN이 된다면 LR가 너무 높고 initialization이 제대로 되지 않은 것이다.
Step 3: Find LR that makes loss go down
- all data, samll weight decay를 통해 100 iteration 이내로 loss가 내려가게 만든다.
- 일반적으로 시도해보기 좋은 LR로는 1e-1, 1e-2, 1e-3, 1e-4가 있다.
Step 4: Coarse grid, train for ~1-5 epochs
- Step 3에서 성능을 낸 Learning rate와 weight decay값을 몇몇으로 추리고 1-5 epochs으로 모델을 학습해본다.
- 일반적으로 좋은 weight decay로는 1e-4, 1e-5가 있다.
Step 5: Refine grid, train longer
- Step 4를 통해 최적의 조합을 찾고 10-20 epoch으로 learning rate decay 없이 학습시켜본다.
Step 6: Look at loss and accuracy curves
- Loss와 accuracy curve를 지켜본다.
- Validation set에서의 accuracy가 감소하지 않으면 좀 더 학습을 시킨다.
- Train과 validation에서의 gap이 너무 크면 overffiting이니 regularization을 강화시킨다.
- train과 validation에서의 gap차이가 없으면 underfitting이니 좀 더 학습시키거나, 더 큰 모델을 사용한다.
- overffiting이 일어나니 너무 오래 훈련시키지 않는다.
Step 7: Go to 5 step
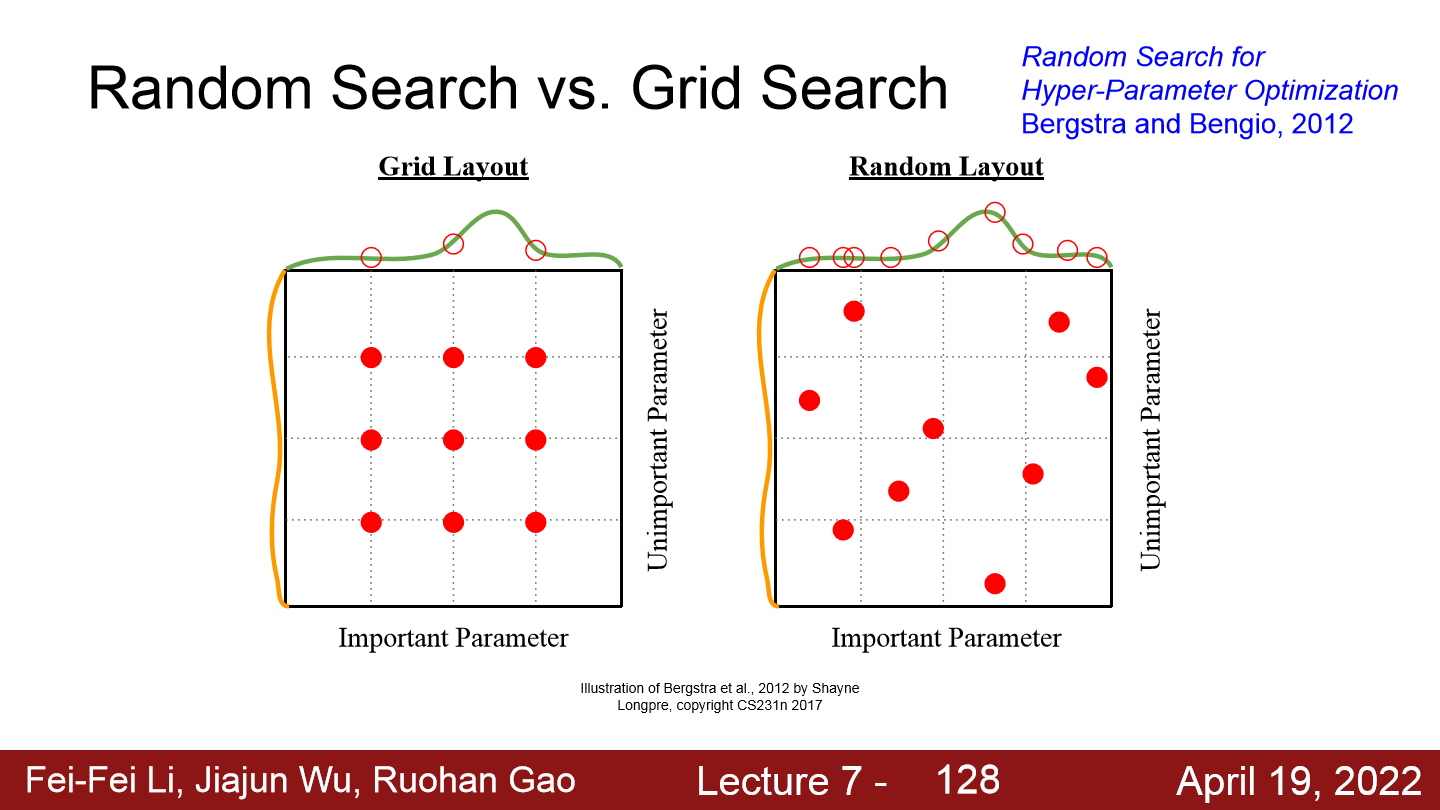
 Random Serach vs Grid Search
Random Serach vs Grid Search - Hyperparameter tuning시 Grid search를 하면 매개변수 그리드를 잘못 선택했을 때 최적의 parameter를 찾을 수 없고, 모든 경우를 test하면 계산량이 많기에 Random search를 하는 것이 좋다고 한다.
Summary
보완점
개인 공부 기록용 블로그 입니다.